znode 경로는 "/" 로 구분된 유니코드 문자열 namespace 구조로 유닉스의 파일시스템 구조와 같다. 다만 상대경로는 지원하지 않고 절대경로만 지원한다.
데이터 접근은 원자성(성공 또는 실패)를 가진다. 클라이언트가 znode에 저장된 데이터를 읽을 때 데이터 전체가 전달되지 않으면 읽기는 실패한다.
쓰기도 마찬가지로 전체를 갱신한다. 즉 append 기능을 지원하지 않는다.
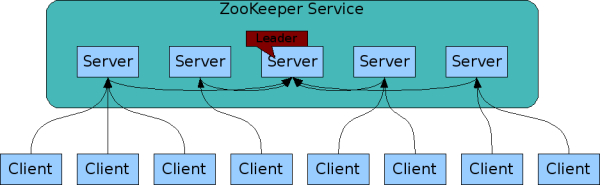
Ensemble
주키퍼는 기본적으로 다수의 노드를 가진 클러스터 구조에서 replicated mode 로 수행되어야 한다.
주키퍼의 이런 클러스터 구조를 앙상블이라 한다.
Zab
주키퍼는 Zab 이라는 두 단계로 동작하는 프로토콜로 앙상블의 장애 상황을 복구해낸다.
Election
앙상블 내의 서버들은 리더를 선출하고, 나머지는 팔로워가 된다. 이는 Raft consensus 의 그것과 같다.
Atomic Broadcast
모든 쓰기 요청은 리더에게 forward 되고, 리더는 팔로워에게 업데이트를 broadcast 한다.
과반수 노드에서 변경을 저장하면 리더는 업데이트 연산을 commit하고, 클라이언트는 업데이터가 성공했다는 응답을 받게 된다.
합의를 위한 포로토콜은 원자적으로 설계되었으므로 변경 결과는 성공, 실패 둘 중 하나다.
모든 쓰기 요청은 리더에게 forward 된다. 그렇다면 여러 클라이언트가 요청한다고 했을때, 리더가 모든 부하를 받아내야 할까?
내가 찾아본 바로는 그렇다. 대신 쓰기 요청을 모아서 batch 처리하고, 읽기 요청은 팔로워 노드에게 보내는 방식으로 처리할 수 있다. 쓰기가 매우 많은 서비스에서는 여러 주키퍼 클러스터를 운용하면서 서비스 레벨에서 데이터가 저장되는 클러스터를 구분함으로써 해결할 수도 있을 것 같다.
ETCD
보통 '엣시디'로 많이 부르는 것 같다. etcd 는 분산 시스템 또는 클러스터의 설정 공유, 서비스 검색 및 스케줄러 조정을 위한 분산형 Key-Value 저장소이다.
etcd 는 무려 k8s 의 구성 데이터, 상태 데이터, 메타데이터를 관리하는 오픈 소스이다.
쿠버네티스는 기반 스토리지로 etcd 를 사용하면서 모든 데이터를 etcd 에 보관하는데, 이를테면 클러스터에 어떤 노드가 몇 개가 있고, 어떤 pod 가 어떤 node 에서 동작하고 있는지가 etcd 에 기록된다.
만약 동작중인 클러스터의 etcd 데이터베이스가 유실되면 컨테이너뿐만 아니라 클러스터가 사용하는 모든 리소스가 미아가 되어버린다.
그럼에도 쿠버네티스에서 etcd를 사용한다는 것은 그만큼 높은 신뢰성을 제공한다는 뜻이기도 하다.
Replicated state machine
Etcd 는 Replicated State Machine 줄여서 RSM 이라고 불리는데, 분산 컴퓨팅 환경에서 서버가 몇 개 다운되어도 잘 동작하는 시스템을 만들고자 할 때 선택하는 방법의 하나이다.
똑같은 데이터를 여러 서버에 계속하여 복제하는 것이며, 이 방법으로 사용하는 머신을 RSM 이라고 한다.
RSM 은 위 그림과 같이 command 가 들어있는 log 단위로 데이터를 처리한다.
데이터의 write 를 log append 라 부르며, 머신은 들어온 log 를 순서대로 처리한다.
하지만, 똑같은 데이터를 여러 서버에 복제해놨다고 해서 모든 게 해결되지는 않는다.
오히려 더 어려운 문제가 생기기도 하는데, Robust 한 RSM을 만들기 위해서는 데이터 복제 과정에 발생할 수 있는 여러 가지 문제를 해결하기 위해 컨센서스(consensus)를 확보하는 것이 핵심이다.
Consensus를 확보한다는 것은 RSM이 아래 4가지 속성을 만족한다는 것과 의미가 같으며, etcd는 이를 위해 Raft 알고리즘을 사용했다.
Safety: 항상 올바른 결과를 리턴해야한다.
Available: 일부 머신에 장애가 발생해도 응답해야한다.
Independent from timing: 네트워크 지연이 발생해도 로그의 일관성이 깨져서는 안된다.
Reactivity: 모든 서버에 복제되지 않았더라도 조건을 만족하면 빠르게 요청에 응답해야한다.
이는 CAP 이론에서의 일관성, 가용성, 분할내성 세 가지를 최대한 만족시키기 위한 것임을 알 수 있다.
Leader Election
etcd 의 리더 선출은 주키퍼와 마찬가지로 Raft 알고리즘과 동일하다.
Log Replication
각 서버는 자신이 가지고 있는 log 의 lastIndex 값을 가지고 있으며, 리더는 여기에 추가로 follower 가 새로운 log 를 써야할 nextIndex 를 알고 있다.
사용자로부터 log append 요청(write)을 리더가 받으면, 자신의 lastIndex 다음 위치에 로그를 기록하고 lastIndex 값을 증가시킨다.
이후에 Heartbeat 시점이 도래하면 모든 서버에게 AppendLogEntry RPC Call 을 보내면서 follower 의 nextIndex 에 해당하는 log 를 함께 보낸다.
정리
주키퍼와 etcd 의 역할은 다르지만 둘 다 raft 알고리즘을 기반으로 분산 시스템에서 목적에 따라 사용된다.
Redis cluster, MongoDB Cluster, Aurora MySQL 등에서도 비슷한 개념이 등장하기 때문에 분산 시스템 환경에서 주어지는 문제들을 각 플랫폼에서 어떻게 해결했는지에 집중하면서 살펴보면 배울 점이 많은 것 같다.





{kind=link}
{kind=link}